Spam Detection
Table of Content
1. Introduction
2. Data Import
2.1. Import Libraries
2.2. Load Emails and Spams
2.3. Handle Attachments and Complex Email Structures
3. Model
3.1. Data Preparation
3.2. Classifier
3.3. Model Tuning
4. Conclusion
1. Introduction
Whether it is to an individual or to a company, spams are typically sent for commercial purpose but can also lead to phishing attacks or scamming. Spams appear in the early 90s and are now accounting for roughly 65% of the email traffic. Companies like Google or Yahoo have developed filtering systems to prevent spams from being listed in their users’ mailbox. In this Notebook, we will go over the implementation of a SPAM detection algorithm.
2. Data Import
For this project, we will be using an email dataset containing spams and regular emails. The dataset is hosted by spamassassin. The dataset documentation can be found here.
2.1 Import Libraries
import os
import tarfile
import urllib
import email
import email.policy
from collections import Counter
from bs4 import BeautifulSoup
from html import unescape
import re
import nltk
from urlextract import URLExtract
import numpy as np
from TAD_tools_v00 import *
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.metrics import precision_score, recall_score
from sklearn.model_selection import GridSearchCV
2.2 Load Emails and Spams
# file locations
ROOT_SITE = 'http://spamassassin.apache.org/old/publiccorpus/'
HAM_URL = ROOT_SITE + "20030228_easy_ham.tar.bz2" # set of regular emails
SPAM_URL = ROOT_SITE + "20030228_spam.tar.bz2" # set of spam emails
FOLDER_LOC = os.path.join('dataset')
def download_data(data_path=FOLDER_LOC, spam_url=SPAM_URL, ham_url=HAM_URL):
'''
Helper function:
- create folders
- load data from urls
'''
print('**LOADING EMAILS AND SPAMS**')
print(' loading data...')
# create folder if necessary
if not os.path.isdir(data_path):
os.mkdir(data_path)
# download spam and ham data
for filename, url in [('ham.tar.bz2', ham_url),('spam.tar.bz2', spam_url)]:
# create full path and check if file has been dowloaded
path = os.path.join(data_path, filename)
if not os.path.isfile(path):
# download file
urllib.request.urlretrieve(url, filename=path)
# open tar file and extract content
with tarfile.open(path, mode='r') as tar_bz2_file:
tar_bz2_file.extractall(path=data_path)
print(' import completed...')
# download emails (spams and regular) and extract content of tar files
download_data()
**LOADING EMAILS AND SPAMS**
loading data...
import completed...
Now that the data has been loaded, we store the spam and non-spam (ham) file names into two separate lists.
# folder paths
HAM_DIR = os.path.join(FOLDER_LOC, "easy_ham")
SPAM_DIR = os.path.join(FOLDER_LOC, "spam")
# collect spam and ham files (a cmds appears when the content of the tar file are retrieved, this file is not included in collection)
ham_filenames = [filename for filename in sorted(os.listdir(HAM_DIR)) if filename!='cmds']
spam_filenames = [filename for filename in sorted(os.listdir(SPAM_DIR)) if filename!='cmds']
# count emails and spams
print('Dataset contains {} emails.'.format(len(ham_filenames)))
print('Dataset contains {} spams.'.format(len(spam_filenames)))
Dataset contains 2500 emails.
Dataset contains 500 spams.
We can retrieve the content of an email by simply opening the file as read-only and printing its content.
# inspect a file to understand its structure
sample_filename = os.path.join(HAM_DIR, ham_filenames[2])
sample_file_content = open(sample_filename, 'r').read()
print(sample_file_content)
From timc@2ubh.com Thu Aug 22 13:52:59 2002
Return-Path: <timc@2ubh.com>
Delivered-To: zzzz@localhost.netnoteinc.com
Received: from localhost (localhost [127.0.0.1])
by phobos.labs.netnoteinc.com (Postfix) with ESMTP id 0314547C66
for <zzzz@localhost>; Thu, 22 Aug 2002 08:52:58 -0400 (EDT)
Received: from phobos [127.0.0.1]
by localhost with IMAP (fetchmail-5.9.0)
for zzzz@localhost (single-drop); Thu, 22 Aug 2002 13:52:59 +0100 (IST)
Received: from n16.grp.scd.yahoo.com (n16.grp.scd.yahoo.com
[66.218.66.71]) by dogma.slashnull.org (8.11.6/8.11.6) with SMTP id
g7MCrdZ07070 for <zzzz@spamassassin.taint.org>; Thu, 22 Aug 2002 13:53:39 +0100
X-Egroups-Return: sentto-2242572-52733-1030020820-zzzz=spamassassin.taint.org@returns.groups.yahoo.com
Received: from [66.218.67.198] by n16.grp.scd.yahoo.com with NNFMP;
22 Aug 2002 12:53:40 -0000
X-Sender: timc@2ubh.com
X-Apparently-To: zzzzteana@yahoogroups.com
Received: (EGP: mail-8_1_0_1); 22 Aug 2002 12:53:39 -0000
Received: (qmail 76099 invoked from network); 22 Aug 2002 12:53:39 -0000
Received: from unknown (66.218.66.218) by m5.grp.scd.yahoo.com with QMQP;
22 Aug 2002 12:53:39 -0000
Received: from unknown (HELO rhenium.btinternet.com) (194.73.73.93) by
mta3.grp.scd.yahoo.com with SMTP; 22 Aug 2002 12:53:39 -0000
Received: from host217-36-23-185.in-addr.btopenworld.com ([217.36.23.185])
by rhenium.btinternet.com with esmtp (Exim 3.22 #8) id 17hrT0-0004gj-00
for forteana@yahoogroups.com; Thu, 22 Aug 2002 13:53:38 +0100
X-Mailer: Microsoft Outlook Express Macintosh Edition - 4.5 (0410)
To: zzzzteana <zzzzteana@yahoogroups.com>
X-Priority: 3
Message-Id: <E17hrT0-0004gj-00@rhenium.btinternet.com>
From: "Tim Chapman" <timc@2ubh.com>
X-Yahoo-Profile: tim2ubh
MIME-Version: 1.0
Mailing-List: list zzzzteana@yahoogroups.com; contact
forteana-owner@yahoogroups.com
Delivered-To: mailing list zzzzteana@yahoogroups.com
Precedence: bulk
List-Unsubscribe: <mailto:zzzzteana-unsubscribe@yahoogroups.com>
Date: Thu, 22 Aug 2002 13:52:38 +0100
Subject: [zzzzteana] Moscow bomber
Reply-To: zzzzteana@yahoogroups.com
Content-Type: text/plain; charset=US-ASCII
Content-Transfer-Encoding: 7bit
Man Threatens Explosion In Moscow
Thursday August 22, 2002 1:40 PM
MOSCOW (AP) - Security officers on Thursday seized an unidentified man who
said he was armed with explosives and threatened to blow up his truck in
front of Russia's Federal Security Services headquarters in Moscow, NTV
television reported.
The officers seized an automatic rifle the man was carrying, then the man
got out of the truck and was taken into custody, NTV said. No other details
were immediately available.
The man had demanded talks with high government officials, the Interfax and
ITAR-Tass news agencies said. Ekho Moskvy radio reported that he wanted to
talk with Russian President Vladimir Putin.
Police and security forces rushed to the Security Service building, within
blocks of the Kremlin, Red Square and the Bolshoi Ballet, and surrounded the
man, who claimed to have one and a half tons of explosives, the news
agencies said. Negotiations continued for about one and a half hours outside
the building, ITAR-Tass and Interfax reported, citing witnesses.
The man later drove away from the building, under police escort, and drove
to a street near Moscow's Olympic Penta Hotel, where authorities held
further negotiations with him, the Moscow police press service said. The
move appeared to be an attempt by security services to get him to a more
secure location.
------------------------ Yahoo! Groups Sponsor ---------------------~-->
4 DVDs Free +s&p Join Now
http://us.click.yahoo.com/pt6YBB/NXiEAA/mG3HAA/7gSolB/TM
---------------------------------------------------------------------~->
To unsubscribe from this group, send an email to:
forteana-unsubscribe@egroups.com
Your use of Yahoo! Groups is subject to http://docs.yahoo.com/info/terms/
NOTE
As shown above, there are a few important features that can be identified from the email content:
- Sender address, date, and time
- Receiver address
- Metadata
- Content data type information
- Title
- Content
Fortunately, there are a few libraries which can be used to handle email content. We will use the most common one to extract specific portion of the email which are relevant to its content.
def load_email(filename, is_spam, data_path=FOLDER_LOC):
'''
Helper function:
- read email file and convert it into email object
'''
subdirectory = 'spam' if is_spam else 'easy_ham'
# open file (read binary)
with open(os.path.join(data_path, subdirectory, filename), 'rb') as mail:
return email.parser.BytesParser(policy=email.policy.default).parse(mail)
# load all files
ham_files = [load_email(filename, False) for filename in ham_filenames]
spam_files = [load_email(filename, True) for filename in spam_filenames]
# verify that the extraction worked
print('Dataset contains {} emails.'.format(len(ham_files)))
print('Dataset contains {} spams.'.format(len(spam_files)))
Dataset contains 2500 emails.
Dataset contains 500 spams.
Now that our files have been extracted and turned into mail object, we can easily access specific fields using get functions.
# check sender information
print(spam_files[10].get_unixfrom().strip())
print('-'*80)
print()
# check file content
print(spam_files[10].get_content().strip())
From hurst@missouri.co.jp Fri Aug 23 11:03:04 2002
--------------------------------------------------------------------------------
Cellular Phone Accessories All At Below Wholesale Prices!
http://202.101.163.34:81/sites/merchant/sales/
Hands Free Ear Buds 1.99!
Phone Holsters 1.98!
Booster Antennas Only $$0.99
Phone Cases 1.98!
Car Chargers 1.98!
Face Plates As Low As 0.99!
Lithium Ion Batteries As Low As 6.94!
http://202.101.163.34:81/sites/merchant/sales/
Click Below For Accessories On All NOKIA, MOTOROLA LG, NEXTEL,
SAMSUNG, QUALCOMM, ERICSSON, AUDIOVOX PHONES At Below
WHOLESALE PRICES!
http://202.101.163.34:81/sites/merchant/sales/
***If You Need Assistance Please Call Us (732) 751-1457***
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
To be removed from future mailings please send your remove
request to: removemenow68994@btamail.net.cn
Thank You and have a super day :)
# check sender information
print(ham_files[10].get_unixfrom().strip())
print('-'*80)
print()
# check file content
print(ham_files[10].get_content().strip())
From spamassassin-devel-admin@lists.sourceforge.net Thu Aug 22 15:25:29 2002
--------------------------------------------------------------------------------
Hello, have you seen and discussed this article and his approach?
Thank you
http://www.paulgraham.com/spam.html
-- "Hell, there are no rules here-- we're trying to accomplish something."
-- Thomas Alva Edison
-------------------------------------------------------
This sf.net email is sponsored by: OSDN - Tired of that same old
cell phone? Get a new here for FREE!
https://www.inphonic.com/r.asp?r=sourceforge1&refcode1=vs3390
_______________________________________________
Spamassassin-devel mailing list
Spamassassin-devel@lists.sourceforge.net
https://lists.sourceforge.net/lists/listinfo/spamassassin-devel
2.3 Handle Attachments and Complex Email Structures
Before processing the email data, the structure of the emails must be inspected for consistency. Indeed, emails can have a variety of structure (no attachements, attachements, attachements with attachements…).
multipart_ham, multipart_spam = 0, 0
for email in ham_files:
multipart_ham+=email.is_multipart()
for email in spam_files:
multipart_spam+=email.is_multipart()
print('{} hams contain multiparts.'.format(multipart_ham))
print('{} spams contain multiparts.'.format(multipart_spam))
92 hams contain multiparts.
98 spams contain multiparts.
The next step consists of inspecting the email structures. The goal is to understand what structures are contained in our dataset and identify if further post-processing is required.
def get_email_structure(mail):
'''
Recursive function used to retrieve email content
'''
# for multipart email, recursion on each part
if mail.is_multipart():
payload = mail.get_payload()
return "multipart({})".format(', '.join([get_email_structure(sub_mail) for sub_mail in payload]))
else:
return mail.get_content_type()
def structures_counter(emails):
'''
Return counter containing key: email structure, value: count
'''
# use counter instead of dictionary to handle key initialization
structures = Counter()
# loop over email -> get structure -> update counter
for email in emails:
structure = get_email_structure(email)
structures[structure] += 1
return structures
structures_counter(ham_files).most_common()
[('text/plain', 2408),
('multipart(text/plain, application/pgp-signature)', 66),
('multipart(text/plain, text/html)', 8),
('multipart(text/plain, text/plain)', 4),
('multipart(text/plain)', 3),
('multipart(text/plain, application/octet-stream)', 2),
('multipart(text/plain, text/enriched)', 1),
('multipart(text/plain, application/ms-tnef, text/plain)', 1),
('multipart(multipart(text/plain, text/plain, text/plain), application/pgp-signature)',
1),
('multipart(text/plain, video/mng)', 1),
('multipart(text/plain, multipart(text/plain))', 1),
('multipart(text/plain, application/x-pkcs7-signature)', 1),
('multipart(text/plain, multipart(text/plain, text/plain), text/rfc822-headers)',
1),
('multipart(text/plain, multipart(text/plain, text/plain), multipart(multipart(text/plain, application/x-pkcs7-signature)))',
1),
('multipart(text/plain, application/x-java-applet)', 1)]
structures_counter(spam_files).most_common()
[('text/plain', 218),
('text/html', 183),
('multipart(text/plain, text/html)', 45),
('multipart(text/html)', 20),
('multipart(text/plain)', 19),
('multipart(multipart(text/html))', 5),
('multipart(text/plain, image/jpeg)', 3),
('multipart(text/html, application/octet-stream)', 2),
('multipart(text/plain, application/octet-stream)', 1),
('multipart(text/html, text/plain)', 1),
('multipart(multipart(text/html), application/octet-stream, image/jpeg)', 1),
('multipart(multipart(text/plain, text/html), image/gif)', 1),
('multipart/alternative', 1)]
Note:
The most common structures are the text/plain and text/html structures. A glance at the structures show that the text/html strcuture is fairly common for spams but not for regular emails.
3. Model
3.1. Data Preparation
Before diving into the dataset, it is important to split it into a training and test sets.
# create y array containing binary classification
X = np.array(ham_files + spam_files)
y = np.array([0] * len(ham_files) + [1] * len(spam_files))
# split dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, shuffle=True)
print('Training set size: \t{}'.format(X_train.shape))
print('Test set size: \t\t{}'.format(X_test.shape))
print('Target train set size: \t{}'.format(y_train.shape))
print('Target test set size: \t{}'.format(y_test.shape))
Training set size: (2400,)
Test set size: (600,)
Target train set size: (2400,)
Target test set size: (600,)
# helper function: retrieve text content from html content
def html_to_plain_text(htlm):
'''
Return plain text from html content.
'''
# replace hyperlink
# flags
# re.I: ignore case
# re.M: multiline
# re.S: make / match newline
htlm = re.sub('<a\s.*?>', ' HYPERLINK ', htlm, flags=re.M | re.S | re.I)
soup = BeautifulSoup(htlm, 'html.parser')
# kill all script and style elements
for script in soup(["script", "style"]):
script.extract() # rip it out
# get text
text = soup.get_text()
# break into lines and remove leading and trailing space on each
lines = (line.strip() for line in text.splitlines())
# break multi-headlines into a line each
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
# drop blank lines
text = '\n'.join(chunk for chunk in chunks if chunk)
return unescape(text)
Let’s try if our script works on some html content. Note that based on our inspection of the email structures, the html strucutre is only used for spams.
# find spam with the text/html structure
html_spam_emails = [email for email in X_train[y_train==1]
if get_email_structure(email) == "text/html"]
# select a candidate
sample_html_spam = html_spam_emails[24]
print(sample_html_spam.get_content().strip()[0:5000],'.....')
<html>
<head>
<meta http-equiv="Content-Type" content="text/html;
charset=iso-8859-1">
</head>
<body bgcolor="#FFFFFF">
<table width="58%" height="257">
<tr valign="top">
<td height="253">
<p><font size="3"><b>Fortunes are literally being made in this new marketplace.</b></font>
</p>
<p>O<font size="3"></font><font size="3">ver <b>$$9 Billion</b> in merchandise
was sold on <b>eBay</b> in 2001 by people just like you - <u>right from
their homes</u>! </font></p>
<p><font size="3">Now you too can learn the secrets of <b>successful selling
</b>on<b> eBay</b> and <b>make a staggering income</b> from the comfort
of <b>your own home</b>. If you are <b>motivated</b>, capable of having
an<b> open mind</b>, and can follow simple directions, then <a href="http://www.nationalbizcorp.com/ebooks">visit
us here</a>. If server busy - <a href="http://www.generaledu.com/ebooks">alternate.</a></font></p>
<p><font size="2">You received this offer as a result of an affiliate relationship
with one of our marketing partners. If you are not interested in future
offers <a href="http://www.nationalbizcorp.com/remove.html">go here.</a></font></p>
</td>
</tr>
</table>
<p> </p>
<p> </p>
<p> </p>
<p> </p>
</body>
</html> .....
print(html_to_plain_text(sample_html_spam.get_content())[:5000], "...")
Fortunes are literally being made in this new marketplace.
Over $$9 Billion in merchandise
was sold on eBay in 2001 by people just like you - right from
their homes!
Now you too can learn the secrets of successful selling
on eBay and make a staggering income from the comfort
of your own home. If you are motivated, capable of having
an open mind, and can follow simple directions, then
HYPERLINK visit
us here. If server busy -
HYPERLINK alternate.
You received this offer as a result of an affiliate relationship
with one of our marketing partners. If you are not interested in future
offers
HYPERLINK go here. ...
We now have a conversion function for html content, we now need a tool to process any email regardless its content and return a string.
def email_to_text(email):
'''
Return text/plain email structure or converted html structure.
'''
# loop over email content to find text/plain or text/html
for part in email.walk():
# retrieve content type
content_type = part.get_content_type()
# skip content if type is not text/plain or text/html
if not content_type in ('text/plain','text/html'):
continue
# try to extract content (error with encoding)
try:
content = part.get_content()
except:
content = str(part.get_payload())
# return plain text or converted html
if content_type == 'text/plain':
return content
else:
html = content
return html_to_plain_text(html)
print(email_to_text(sample_html_spam)[:200], "...")
Fortunes are literally being made in this new marketplace.
Over $$9 Billion in merchandise
was sold on eBay in 2001 by people just like you - right from
their homes!
Now you too can learn the secrets o ...
In order to generalize the prediction of our model, we are going to use a stemmer (from nltk). A stemmer replaces a word by its root word. Let’s look at an example.
stemmer = nltk.PorterStemmer()
for w in ('association', 'associated', 'associates', 'company', 'corporation', 'incorporated'):
print ('{0}: {1}'.format(w,stemmer.stem(w)))
association: associ
associated: associ
associates: associ
company: compani
corporation: corpor
incorporated: incorpor
One of the typical transformation when dealing with texts is to remove stop words (most common english words). Thankfully, the NLTK library contains a list of stopwords.
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
nltk.download('stopwords')
[nltk_data] Downloading package stopwords to
[nltk_data] /Users/thibault.dody/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
True
class emailToWordCount(BaseEstimator, TransformerMixin):
def __init__(self, replace_urls=True, stemming=True, replace_numbers=True, lower_case=True, remove_punctuation=True, remove_stop_words=True):
self.replace_urls = replace_urls
self.stemming = stemming
self.replace_numbers = replace_numbers
self.lower_case = lower_case
self.remove_punctuation = remove_punctuation
self.remove_stop_words = remove_stop_words
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
X_transformed = []
for email in X:
# retrieve text content
text = email_to_text(email) or ""
# convert url to token
if self.replace_urls:
extractor = URLExtract()
for url in list(set(extractor.find_urls(text))):
text = text.replace(url, ' URL ')
# replace float, integers, scientific notation, and percent
if self.replace_numbers:
text = re.sub(r'([-+]?\d*\.?\d+[eE]?[+-]?\d*[%]?)', 'NUMBER', text)
# switch content to lower case
if self.lower_case:
text = text.lower()
# remove punctuation
if self.remove_punctuation:
text = re.sub(r'\W+', ' ', text, flags=re.M)
# split email
email_spilt = text.split()
# remove stop words (english)
if self.remove_stop_words:
stop_words = set(stopwords.words('english'))
email_split_clean = []
for word in email_spilt:
if not word in stop_words:
email_split_clean.append(word)
email_spilt = email_split_clean
word_counts = Counter(email_spilt)
# replace words using stemming
if self.stemming:
stemmed_word_count = Counter()
for word, count in word_counts.items():
stemmed_word = stemmer.stem(word)
stemmed_word_count[stemmed_word] += count
word_counts = stemmed_word_count
X_transformed.append(word_counts)
return np.array(X_transformed)
X_sample = X_train[0:2]
X_sample_wordcounts = emailToWordCount().fit_transform(X_sample)
X_sample_wordcounts
array([Counter({'chuck': 1, 'murcko': 1, 'wrote': 1, 'stuff': 1, 'yawn': 1, 'r': 1}),
Counter({'christian': 3, 'jefferson': 2, 'superstit': 2, 'one': 2, 'half': 2, 'rogueri': 2, 'teach': 2, 'jesu': 2, 'interest': 1, 'quot': 1, 'url': 1, 'thoma': 1, 'examin': 1, 'known': 1, 'word': 1, 'find': 1, 'particular': 1, 'redeem': 1, 'featur': 1, 'alik': 1, 'found': 1, 'fabl': 1, 'mytholog': 1, 'million': 1, 'innoc': 1, 'men': 1, 'women': 1, 'children': 1, 'sinc': 1, 'introduct': 1, 'burnt': 1, 'tortur': 1, 'fine': 1, 'imprison': 1, 'effect': 1, 'coercion': 1, 'make': 1, 'world': 1, 'fool': 1, 'hypocrit': 1, 'support': 1, 'error': 1, 'earth': 1, 'six': 1, 'histor': 1, 'american': 1, 'john': 1, 'e': 1, 'remsburg': 1, 'letter': 1, 'william': 1, 'short': 1, 'becom': 1, 'pervert': 1, 'system': 1, 'ever': 1, 'shone': 1, 'man': 1, 'absurd': 1, 'untruth': 1, 'perpetr': 1, 'upon': 1, 'larg': 1, 'band': 1, 'dupe': 1, 'import': 1, 'led': 1, 'paul': 1, 'first': 1, 'great': 1, 'corrupt': 1})],
dtype=object)
The emailToWordCount is the first segment of the full transformation pipeline. The second stage consists of a vectorizer. The goal is to convert the counter generated for each email into a vector of size \(N\) where \(N\) is the size of our vocabulary. The fit function will use the content of the train set to define what are the most frequent words.
from scipy.sparse import csr_matrix
class WordCountToVector(BaseEstimator, TransformerMixin):
def __init__(self, vocabulary_size=10000, cap_size=10):
self.vocabulary_size = vocabulary_size
self.cap_size = cap_size
def fit(self, X, y=None):
total_count = Counter()
for word_count in X:
for word, count in word_count.items():
total_count[word] += min(count, self.cap_size)
most_common = total_count.most_common()[:self.vocabulary_size]
self.most_common = most_common
self.vocabulary_ = {word:index+1 for index, (word, count) in enumerate(most_common)}
return self
def transform(self, X, y=None):
# array mapping: rows, cols, data
# then create array using the mapping
rows = [] # one row per email
cols = [] # one col per word
data = [] # word counter
for row, word_count in enumerate(X):
for word, count in word_count.items():
rows.append(row)
cols.append(self.vocabulary_.get(word,0)) # <OOV> is index 0 (key is not found)
data.append(count)
# csr_matrix((data, ij), [shape=(M, N)]
return csr_matrix((data, (rows, cols)), shape=(len(X), self.vocabulary_size+1))
A small sample of email is used to test the transformation.
vocab_transformer = WordCountToVector(vocabulary_size=10, cap_size=20)
X_sample_vectors = vocab_transformer.fit_transform(X_sample_wordcounts)
X_sample_vectors
<2x11 sparse matrix of type '<class 'numpy.int64'>'
with 12 stored elements in Compressed Sparse Row format>
X_sample_vectors.toarray()
array([[ 4, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1],
[63, 3, 2, 2, 2, 2, 2, 2, 2, 0, 0]], dtype=int64)
As shown above, each email is converted into a sparse vector. The weights of the vector correspond to the number of occurrence of the specific word. The index 0 corresponds to words not contained in the vocabulary.
vocab_transformer.vocabulary_
{'christian': 1,
'jefferson': 2,
'superstit': 3,
'one': 4,
'half': 5,
'rogueri': 6,
'teach': 7,
'jesu': 8,
'chuck': 9,
'murcko': 10}
The mapping between the model vocabulary and the weight index in the \(X\) matrix is stored in a dictionary.
3.2. Classifier
Let’s start to make predictions with a simple model, a logistic regression. It is common to assess the potential of a model by simply training a model using its default hyperparameters. If the results are promising, time can then be invested to tune the model.
# Create full pipeline email -> wordCount -> countVector
preprocess_pipeline = Pipeline([
("email_to_wordcount", emailToWordCount()),
("wordcount_to_vector", WordCountToVector()),
])
# transform the data
X_train_transformed = preprocess_pipeline.fit_transform(X_train)
# create model and perform cross-validation
log_clf = LogisticRegression(solver="liblinear", random_state=42)
score = cross_val_score(log_clf, X_train_transformed, y_train, cv=3, verbose=1, n_jobs=4)
[Parallel(n_jobs=4)]: Using backend LokyBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 3 out of 3 | elapsed: 1.6s finished
print('Mean accuracy over {0} folds: {1:.2f}%'.format(len(score),score.mean()*100))
print('Standard deviation accuracy over {0} folds: {1:.2f}%'.format(len(score),score.std()*100))
Mean accuracy over 3 folds: 98.96%
Standard deviation accuracy over 3 folds: 0.21%
Based on the above, it appears that the logistic regression performs relatively well. With a mean accuracy of 98.96% on a three-fold cross validation, this simple model yields promising results.
3.3. Model Tuning
Now that we have identified a promising model, we are going to tune its hyperparameters. To do so, let’s create a pipeline containing three stages.
- Email to Word Count: we will tune the stemming (True or False) and the use of stop words (True or False)
- Word Count to Vector: we will tune the cap size used to define the most used words
- Logistic Regression: we will tune the regularization parameter (C) and the penalty type (L1 or L2)
# create full pipeline
full_pipeline = Pipeline([
("email_to_wordcount", emailToWordCount()),
("wordcount_to_vector", WordCountToVector()),
("clf_log_reg",LogisticRegression())
])
# create candidates value for hyperparameters
params = {
"email_to_wordcount__stemming":[True, False],
"email_to_wordcount__remove_stop_words":[True, False],
"wordcount_to_vector__cap_size":[10, 25, 50],
"clf_log_reg__penalty":['l1', 'l2'],
"clf_log_reg__C":np.logspace(0, 4, 5)
}
# create grid-search
clf = GridSearchCV(full_pipeline, params, cv=3, verbose=3, n_jobs=4)
# fit grid-search
best_model = clf.fit(X_train, y_train)
[Parallel(n_jobs=4)]: Using backend LokyBackend with 4 concurrent workers.
Fitting 3 folds for each of 120 candidates, totalling 360 fits
[Parallel(n_jobs=4)]: Done 24 tasks | elapsed: 15.7min
[Parallel(n_jobs=4)]: Done 120 tasks | elapsed: 82.0min
[Parallel(n_jobs=4)]: Done 280 tasks | elapsed: 172.9min
[Parallel(n_jobs=4)]: Done 360 out of 360 | elapsed: 210.7min finished
/anaconda3/lib/python3.6/site-packages/sklearn/linear_model/logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
Once the tuning has been performed, we can inspect what model obtained the best accuracy on the test fold and we can also print the best combination of hyperparameters.
print('Grid Search best accuracy: {:.2f}%\n'.format(clf.best_score_*100))
print('Grid Search best parameters:')
for param, value in clf.best_params_.items():
print(' ',param,'=', value)
Grid Search best accuracy: 99.21%
Grid Search best parameters:
clf_log_reg__C = 1.0
clf_log_reg__penalty = l2
email_to_wordcount__remove_stop_words = True
email_to_wordcount__stemming = True
wordcount_to_vector__cap_size = 50
As shown above, our model reached an accuracy of 99.21% on the test fold. This is a slight improve compared to our previous model.
# create a model based on the best combination of parameters
best_clf = LogisticRegression(solver="liblinear", random_state=42, C=1.0, penalty='l2')
best_clf.fit(X_train_transformed, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=42, solver='liblinear', tol=0.0001, verbose=0,
warm_start=False)
4. Conclusion
# make prediction on training set
y_train_pred = best_clf.predict(X_train_transformed)
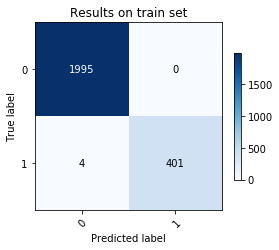
print('Results on training set\n')
plot_confusion_matrix(y_train, y_train_pred, np.array([0,1]), title='Results on train set')
print('Precision: {:.2f}%'.format(precision_score(y_train, y_train_pred)*100))
print('Recall: {:.2f}%'.format(recall_score(y_train, y_train_pred)*100))
Results on training set
Precision: 100.00%
Recall: 99.01%
# make prediction on test set
X_test_transformed = preprocess_pipeline.transform(X_test)
y_test_pred = best_clf.predict(X_test_transformed)
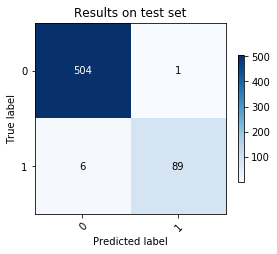
print('Results on test set\n')
plot_confusion_matrix(y_test, y_test_pred, np.array([0,1]), title='Results on test set')
print('Precision: {:.2f}%'.format(precision_score(y_test, y_test_pred)*100))
print('Recall: {:.2f}%'.format(recall_score(y_test, y_test_pred)*100))
Results on test set
Precision: 98.89%
Recall: 93.68%
Note on the metrics:
The basic metric for this problem is the accuracy (i.e. the ratio of the number of correct predictions and the number of total predictions). However, for cases such as email spam, one can decide to look at the problem from a different angle. Indeed, should we be concern about the type of errors the model is making? For the case of spam detection, do we care more if an email is incorrectly specified as a spam or if a spam is incorrectly specified as a normal email. It seems that the misclassification of emails as spams can cause the most harm to a user (professionally or personally). Indeed, users tend to never look into their spam folder. So if an important email is classified as spam, our users may be more impacted than having one spam in his folder. One additional aspect of this problem is human performance. Even if a spam is incorrectly filtered and ends up in the user’s mailbox, human are good at identifying text content and therefore detect spam content. In conclusion, for two models leading to the same accuracy, the model with the highest Precision (TP / [TP+FP] ) is to be chosen.
One of the benefits of using linear models such as linear regressions or logistic regressions lies in their interpretability. We can now look at the model weights and relate them to the vocabulary words they stand for.
# Extract vocabulary from pipeline
word_to_index_vocab = preprocess_pipeline.named_steps['wordcount_to_vector'].vocabulary_
index_to_word_vocab = dict(zip(word_to_index_vocab.values(), word_to_index_vocab.keys()))
sorted_weights = np.argsort(best_clf.coef_)
# print the 20 words with the largest weights leading to the 'ham' classification
for loc in sorted_weights[0,-20:]:
print('index: {0}, word: {1}, coeff: {2:.3f}'.format(loc, index_to_word_vocab[loc], best_clf.coef_[0,loc]))
index: 413, word: repli, coeff: 0.413
index: 3283, word: vip, coeff: 0.430
index: 411, word: card, coeff: 0.433
index: 96, word: site, coeff: 0.435
index: 128, word: offer, coeff: 0.437
index: 137, word: today, coeff: 0.466
index: 987, word: adult, coeff: 0.468
index: 37, word: receiv, coeff: 0.469
index: 1474, word: freebsd, coeff: 0.483
index: 474, word: guarante, coeff: 0.514
index: 12, word: email, coeff: 0.524
index: 235, word: access, coeff: 0.529
index: 9687, word: 全球email地址销售网, coeff: 0.530
index: 18, word: free, coeff: 0.634
index: 62, word: remov, coeff: 0.717
index: 4982, word: webmak, coeff: 0.744
index: 512, word: visit, coeff: 1.006
index: 55, word: pleas, coeff: 1.067
index: 40, word: hyperlink, coeff: 1.366
index: 81, word: click, coeff: 1.801
# print the 20 words with the largest weights leading to the 'spam' classification
for loc in sorted_weights[0,0:20]:
print('index: {0}, word: {1}, coeff: {2:.3f}'.format(loc, index_to_word_vocab[loc], best_clf.coef_[0,loc]))
index: 23, word: date, coeff: -1.836
index: 22, word: wrote, coeff: -1.253
index: 139, word: numbernumbertnumb, coeff: -1.149
index: 4, word: use, coeff: -0.727
index: 27, word: spamassassin, coeff: -0.653
index: 210, word: suppli, coeff: -0.614
index: 34, word: group, coeff: -0.570
index: 21, word: rpm, coeff: -0.514
index: 31, word: think, coeff: -0.511
index: 47, word: said, coeff: -0.509
index: 124, word: sep, coeff: -0.489
index: 50, word: say, coeff: -0.489
index: 2, word: url, coeff: -0.471
index: 19, word: user, coeff: -0.434
index: 48, word: could, coeff: -0.422
index: 46, word: spam, coeff: -0.408
index: 41, word: _______________________________________________, coeff: -0.408
index: 106, word: write, coeff: -0.399
index: 11, word: messag, coeff: -0.394
index: 35, word: tri, coeff: -0.389